

Tipos de Machine Learning

Omar Bahena Bojórquez
BEx CFE
Software Expert
El machine learning o aprendizaje automático es un área dentro del campo de la inteligencia artificial (IA), un tema relevante en la actualidad. En este artículo descubrirás ¿a qué nos referimos cuando escuchamos o leemos el término?
En particular, el machine learning se ocupa de crear modelos computacionales que aprenden de los datos con los que se les entrena y de las tendencias que derivan de éstos. Algunas aplicaciones son los modelos que pueden obtener un resultado numérico de un conjunto histórico de cantidades como son transacciones bancarias, detectar anomalías para detección de fraudes o patrones clave dentro del código fuente de nuestros proyectos e incluso se pueden utilizar en conjuntos de datos dispersos para que se agrupen según sus características comunes.
Técnicas de aprendizaje automático
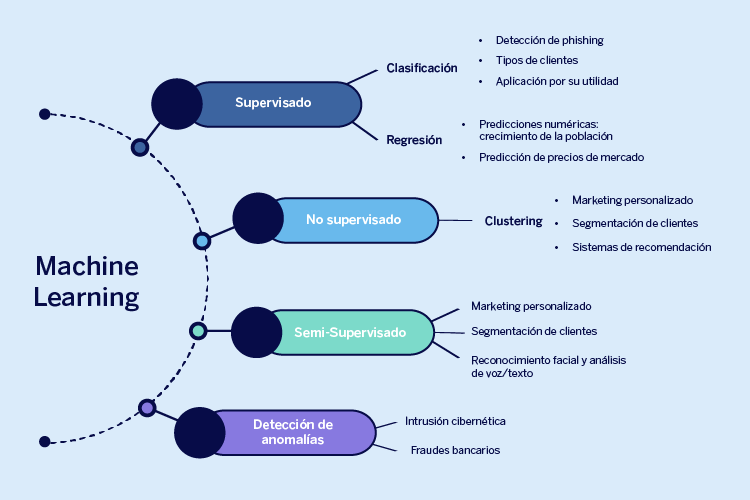
En machine learning una etiqueta se refiere a ciertos metadatos que guían el entrenamiento del algoritmo o modelo, a modo de ejemplos que dirigen el aprendizaje. Existen diversas técnicas de aprendizaje automático, éstas se clasifican principalmente en dos grupos que se distinguen entre sí por los datos que contienen, están acompañados de “etiquetas” o carecen de ellas. Los modelos que usan datos etiquetados se les conoce como de aprendizaje supervisado, y los que no tienen guías predefinidas son los modelos de aprendizaje no supervisado.
También existen los algoritmos semi-supervisados, pero éstos sólo son combinaciones de modelos de ambos tipos. Cada grupo se asocia con tipos de problemas que suelen resolver, y son:
Aprendizaje Supervisado
Problemas de regresión
Como antes mencionamos, algunos modelos devuelven resultados numéricos a partir de “n” entradas que van cambiando a través del tiempo. Hablamos de los problemas de regresión, que buscan obtener una función que generalice la relación entre variables de entrada y la salida que deseamos automatizar u obtener de forma predictiva en casos futuros.
Problemas de clasificación
En el caso de los problemas de clasificación, se usan los datos conocidos y que se relacionan con alguna categoría o clase, por ejemplo podríamos pensar en las características que identifican a distintos animales como el número de patas, el sonido que emiten, su tamaño, etc.
En el ámbito tecnológico se puede hablar de los tipos de cliente, de aplicación por su utilidad, de herramientas, entre otros. La detección de phishing en el buzón corporativo es una aplicación potencial de los algoritmos de clasificación, ya sea en spam/no spam (clasificación binaria) o con varias clases (clasificación multiclase).
Aprendizaje no supervisado
Problemas de agrupamiento
Para abordarlos se recurre a técnicas llamadas comúnmente de clustering, siendo un clúster un grupo distinguible de otro en el que no existe conocimiento previo de los datos, por lo cual se van infiriendo sus relaciones y se afinan con múltiples iteraciones.
Detección de anomalías
Por último, pero no menos importante, están las técnicas de detección de anomalías. En la industria financiera representan una gran oportunidad ya que son aquellas que destacan los datos fuera de lo común dentro de un conjunto, con lo que contribuyen a la identificación de conductas sospechosas para eliminarlas o estudiarlas a profundidad con el objetivo de conocer sus causas.
¿Cuál es el mejor algoritmo de machine learning?
La respuesta es simple, depende siempre del tipo de problema al que nos enfrentemos, de la cantidad y calidad de los datos (las C’s del dato, como también se les conoce) que se tengan disponibles, así como los objetivos que nos hayamos trazado para analizar. Teniendo claros estos puntos resultará más sencilla la elección de un modelo u otro para su implementación.
Conclusiones
En resumen y para tener más claro en la práctica cómo podemos saber que se está hablando de algoritmos de machine learning te compartimos las siguientes técnicas:
- Algoritmos de regresión: lineal, polinómica, logarítmica.
- Algoritmos de clasificación: binario, multiclase, Naive-Bayes, máquinas de vector de soporte (SVM), árboles de decisión, random forests y redes neuronales (éstas últimas tres también se usan en regresión).
- Algoritmos de agrupamiento: k-means, agrupamiento jerárquico (dendrogramas).
- Algoritmos de detección de anomalías: selección de hiperparámetros, técnicas estadísticas como el intercuartil (IQR), isolation forest.
Los puntos 1 y 2 se engloban en el aprendizaje supervisado, mientras que 3 y 4 son propios del aprendizaje no supervisado.
Finalmente, la mayoría de los algoritmos se pueden utilizar los lenguajes por excelencia del rubro de data science: Python y R. Cada uno provee bibliotecas de funciones para que puedan experimentar con problemas reales. En el caso de Python es muy utilizado el IDE Anaconda que incluye las principales herramientas como son Scikitlearn, Pandas, Seaborn, Jupyter, Spyder, Rstudio, Tensorflow, Keras, entre otras.
Fuente: Elaboración propia con base en curso “Aprendizaje automático” durante maestría en inteligencia artificial, UNIR (2024).
Leave a Reply